AI is reshaping how Data and Information is packaged, embedded, and monetised. For Data & Information businesses, the challenge is no longer whether to “do AI,” but how to structure AI features and licensing rights without permanently transferring value. In this piece, we outline how to monetize AI while preserving long-term strategic control.
For Data & Information businesses, AI presents both real growth opportunities and structural risk. Handled well, AI can increase customer stickiness, expand use cases, and unlock new revenue streams. Handled poorly, it can permanently relocate value into someone else’s model.
The difference lies in where your value truly sits as we explain in our value layers white paper here.
Businesses built on proprietary, differentiated datasets are well positioned to use AI to strengthen their advantage. Those reliant on aggregating publicly available information face greater exposure and must differentiate through analytics and workflow integration, and decision support.
AI is changing how customers consume data and what they use it for. Increasingly, they want data embedded into AI workflows and decision tools. That shift makes packaging, usage rights, and training decisions strategically significant, because the wrong choices can weaken the very layer that drives your pricing power.
In practice, most Data & Information businesses are pursuing one or more of three approaches:
- Building AI into their own platforms to strengthen their role in customer workflows
- Licensing data for use in customers’ internal AI systems under controlled terms
- Partnering with frontier LLM providers where data may be used within large-scale AI products
Linked to these approaches, three commercial questions now dominate:
- How should we monetise the AI features built in house on top of our data?
- What AI usage rights should we grant to direct customers, particularly around inference vs. training, and how should those rights be monetized?
- Should we license our data to frontier LLM providers for model training?
The businesses that get these questions right are not the ones that implement AI the fastest. They are the ones that understand where their value truly sits, while protecting and monetizing it accordingly.
In house AI features
Many Data & Information businesses have launched or are in the process of developing AI-powered features into their core platforms sitting on top of their proprietary data to enhance customer experiences. For example:
- In academic research, Elsevier has integrated AI into ScienceDirect and Scopus, enabling researchers to ask plain-English questions and receive structured summaries across journal databases.
- In financial and market intelligence, S&P Global and Moody’s have integrated AI into their platforms to help users surface relevant companies, risks, and signals more quickly.
- In legal information, LexisNexis and Thomson Reuters have integrated AI into research platforms such as Lexis+ and Westlaw to help professionals identify relevant cases and extract insights from complex documents.
Monetization potential
Basic generative AI capabilities, such as summarisation and natural language search are rapidly becoming expected features. Customers show limited incremental willingness to pay for GPT-style functionality, particularly when public LLMs are widely available at low cost.
Where monetization potential is stronger is in tools that combine proprietary data and domain expertise to help customers make materially better decisions - for example, scenario modelling or tools that directly support pricing, risk, or investment decisions.
However, building AI features is not automatically value-accretive.
Two critical considerations apply:
Your “right to win”: Your “right to win” describes the likelihood that your AI offering becomes the preferred tool of choice versus customers simply saying, “just give us your data.”
Many sophisticated customers are building in-house AI solutions, bringing together multiple data inputs. Given that, what distinct value does your solution provide to warrant their investment??
Don’t assume that if you build it, customers will want to buy it.
Defending your value layer: How you attribute value relates to the way you apportion value (and hence price) across your AI tools vs. underlying content. In the race to drive adoption of new AI tools, there is a risk that Data & Information businesses give away too much of their underlying content.
Given the pace at which the market for AI tools is evolving, it’s critical that Data & Information businesses don’t lose sight of their value layer, defending first and foremost the value of their underlying content, particularly in instances where their “right to win” is lower.
Packaging your AI features
Most Data Information businesses position their AI features amongst their existing web-interface packaging line-up. Broadly speaking we see three archetypal types of features, based on their relevance and value, which should be integrated as follows:
- Widely relevant / low-to-moderate value → roll into existing packages for modest price increase
- Widely relevant / high value → roll into existing (premium) package with significant price increase or use as the basis to create new premium tier
- Niche appeal / high value → sell as premium add-on or standalone offering
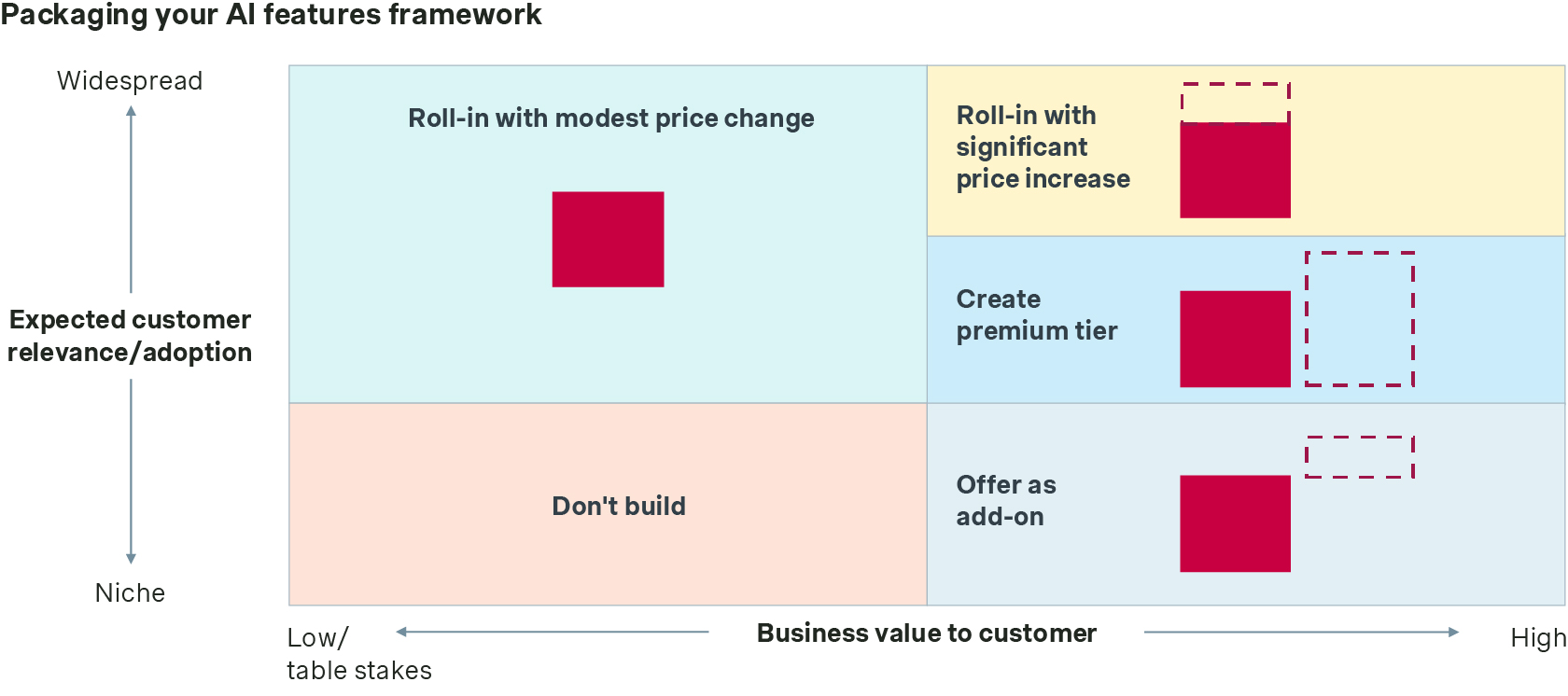
Critically, it’s important that Data & Information businesses preserve the integrity of their underlying content packaging when adding AI features, to prevent there being a “back door” to a wider array of content than has otherwise been purchased.
Pricing your AI features
AI pricing should reflect how value is created.
Most Data & Information businesses tie the price of their web interface, at least in part, to the breadth of access they grant (e.g. per user, per team, enterprise wide).
Broadly speaking, where your AI tools enhance the effectiveness and/or creativity of users, they can be priced as % up-sell on the underlying user-based model.
There are three situations though where alternative models need to be considered:
- When the tools enhance the efficiency of the users, to the extent that fewer users are likely to be needed (thus eroding your underlying price model)
- When the value delivered scales entirely independently of the number of users
- When variable costs are material and/or highly variable between customers
In these situations, alternative pricing approaches such as usage-based pricing need to be considered.
AI usage and license rights for direct customers
This is currently the most active and commercially sensitive topic in the sector.
At a minimum, contracts must clearly define how customers may and may not use your data in AI systems. Without this clarity, you risk losing control over training, redistribution, and future monetization.
Inference vs. training: the critical divider
The single most important distinction is whether your data is used at inference time or training time:
- Inference (e.g. internal GPTs, RAG) uses data at query time without updating the underlying model weights
- Training incorporates your data into model weights in a way that cannot realistically be reversed
Inference preserves value. Training transfers it.
Once data is used to train a model, the embedded knowledge cannot meaningfully be removed. A deletion clause does not “untrain” a system.
For most Data & Information businesses, inference should be the default. Training should be the exception.
Across the market, vendors are increasingly permitting inference within controlled enterprise environments while remaining cautious about training.
Recent announcements illustrate how this is evolving in practice. For example, LSEG has announced a collaboration with OpenAI that allows financial professionals to access LSEG datasets within ChatGPT through controlled API connections, enabling AI-assisted workflows without transferring the underlying data into the model.
As one sector CEO put it: “AI can sit on top of our data. We do not want our data to disappear into someone else’s AI”
Some providers have gone further, declining to permit AI usage altogether while they continue to learn their customers’ new needs, observe how the sector evolves, and refine their commercial approaches.
How inference is licensed and monetized
Inference rights are rarely granted as blanket “AI permissions.” Instead, they are typically defined and priced around specific business use cases.
Common permitted use cases include:
- Internal research and synthesis
- Risk modelling
- Forecasting and scenario analysis
- Compliance screening
These permissions are typically monetized through:
- Premium AI add-on licences layered on top of an existing machine-to-machine or API licence
- Defined uplifts tied to specific approved use cases
- Explicit prohibitions on training models, reselling data, or building it into other commercial offerings
The commercial principle is straightforward: inference increases the intensity and value of data usage, and should be priced accordingly, but within clearly bounded rights.
When training might make sense
Training is not automatically wrong, but it is high risk.
It may make sense when:
- The content is non-core or under-monetized
- The economic shelf life is limited
- The content is not central to competitive differentiation
- The training purpose is narrowly defined
- Compensation is significant and proportionate to long term risk
Where it is permitted, it is almost always tightly scoped and defined around a specific use case. For example, some publishers have permitted tightly scoped use of content to help AI systems better recognize specialist terminology and industry-specific language, improving the accuracy of responses, while explicitly excluding broader model training rights. These arrangements are designed to participate in ecosystem development without transferring the full economic value of the dataset.
However, where data forms the core value layer, particularly if it is decision-critical or structurally reusable, training can permanently shift competitive advantage.
The more reusable the data, the greater the risk.
Licensing to frontier LLM providers
Licensing content to frontier LLM providers remains the most debated AI monetization decision in the sector.
Several high-profile agreements have been announced:
- Taylor & Francis licensed selected journal content to Microsoft.
- Wiley licensed journal content to OpenAI and Anthropic.
- Axel Springer, News Corp, and the Financial Times licensed news content to OpenAI for use within ChatGPT.
- The Associated Press licensed portions of its news archive to OpenAI.
Although the commercial details vary, these agreements tend to be:
- Non-exclusive, meaning publishers retain the right to license elsewhere
- Limited to defined datasets, often archives, rather than full, continuous access to updated datasets
- Structured with usage boundaries, including restrictions on redistribution or resale
- Accompanied by attribution requirements, meaning that if content is surfaced or summarised in the AI system, users are directed back to the original source
By number, such agreements remain the exception rather than the norm because of the risks outlined earlier, namely that once data is incorporated into a frontier model’s weights, it cannot realistically be reversed.
Businesses considering such agreements must evaluate:
- Long-term substitution risk
- Whether attribution e.g. citations meaningfully preserve brand visibility
- The scope and boundaries of the dataset licensed
- Whether short-term revenue compensates for irreversible value transfer
The key question is whether the economics justify relocating part of your value layer into someone else’s model.
Control often matters more than monetization.
Conclusion
AI presents genuine opportunity and meaningful risk for Data & Information businesses.
The most successful businesses will:
- Use AI to makes their offerings more essential to customers, not easier to bypass
- Default to inference and tightly define when, if ever, training is permitted
- License AI use around clear business use cases and price them accordingly
- Prioritize long-term control over short-term monetization
AI should deepen your moat, not flatten it.
We are currently working with several Data & Information businesses to design AI monetization and licensing frameworks that balance commercial opportunity with long-term strategic control.
If you would like to discuss your packaging, pricing, or AI licensing strategy, please contact our Data & Information sector experts today.